GPU – 加速計算是數(shù)據(jù)從業(yè)者和企業(yè)的游戲規(guī)則改變者,但利用 GPU 對數(shù)據(jù)專業(yè)人士來說可能是一項挑戰(zhàn)。RAPIDS通過熟悉的界面抽象加速數(shù)據(jù)科學(xué)的復(fù)雜性,從而解決了這些挑戰(zhàn)。使用 RAPIDS 時,從業(yè)者可以快速加速 NVIDIA GPU 上的數(shù)據(jù)科學(xué)工作負載,將數(shù)據(jù)加載、處理和培訓(xùn)等操作從數(shù)小時減少到數(shù)秒。
管理大規(guī)模數(shù)據(jù)科學(xué)基礎(chǔ)設(shè)施帶來了重大挑戰(zhàn)。有了 Saturn 云,管理基于 GPU 的基礎(chǔ)設(shè)施變得更加容易,使從業(yè)者和企業(yè)能夠?qū)W⒂诮鉀Q其業(yè)務(wù)挑戰(zhàn)。
什么是 Saturn Cloud ?
Saturn Cloud 是一個端到端平臺,可通過云中的可擴展計算資源訪問基于 Python 的數(shù)據(jù)科學(xué)。 Saturn Cloud 為移動到云提供了一條簡單的路徑,無需成本、設(shè)置或基礎(chǔ)設(shè)施工作。這包括使用預(yù)構(gòu)建的環(huán)境訪問配備 GPU 的計算資源,預(yù)構(gòu)建的環(huán)境包括 RAPIDS 、 PyTorch 和 TensorFlow 等工具。
用戶可以在托管的 JupyterLab 環(huán)境中編寫代碼,或者使用 SSH 連接自己的 IDE (集成開發(fā)環(huán)境)。隨著數(shù)據(jù)量的增加,用戶可以擴展到支持 GPU 的Dask集群,以便在分布式計算機網(wǎng)絡(luò)上執(zhí)行代碼。開發(fā)數(shù)據(jù)管道、模型或儀表板后,用戶可以將其部署到持久位置,或創(chuàng)建作業(yè)以按計劃運行它。
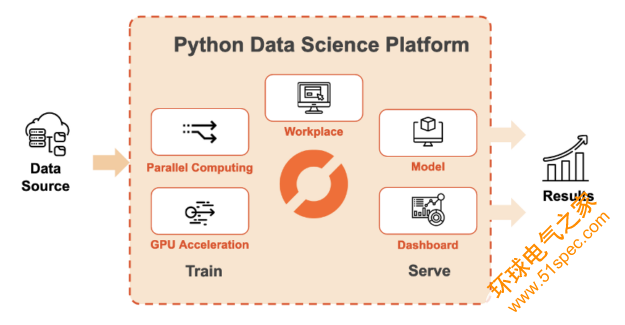
圖 1 : Saturn Cloud 為大規(guī)模數(shù)據(jù)科學(xué)提供了一個基于 Python 的平臺。
除了 Saturn Cloud 的企業(yè)產(chǎn)品外, Saturn Cloud 還提供托管產(chǎn)品,任何人都可以免費開始 GPU – 加速數(shù)據(jù)科學(xué)。托管免費計劃每月包括 10 小時的 Jupyter 工作區(qū)和 3 小時的 Dask 集群。如果需要更多資源,可以升級到托管的 Pro plan 和現(xiàn)收現(xiàn)付。
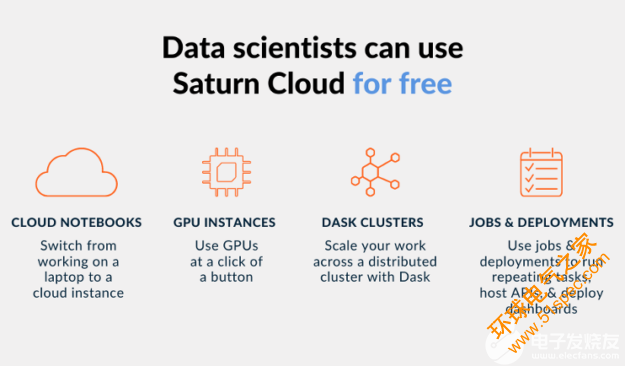
圖 2 :用戶可以在 Saturn 云主機上訪問筆記本電腦、 GPU s 、集群和調(diào)度工具。
Saturn Cloud 為 GPU 加速數(shù)據(jù)科學(xué)應(yīng)用提供了一個易于使用的平臺。借助該平臺, GPU 成為日常數(shù)據(jù)科學(xué)堆棧的核心組件。
開始使用 Saturn Cloud 上的 RAPIDS
在 Saturn Cloud 上創(chuàng)建免費帳戶后,您可以快速開始使用 RAPIDS 。在本節(jié)中,我們將展示如何使用 Saturn Cloud 在紐約出租車數(shù)據(jù)上使用 RAPIDS 訓(xùn)練機器學(xué)習(xí)模型。然后我們進一步在 Dask 集群上運行 RAPIDS 。通過結(jié)合 RAPIDS 和 Dask ,您可以使用多節(jié)點 GPU 系統(tǒng)網(wǎng)絡(luò)來訓(xùn)練模型,其速度遠遠快于使用單個 GPU 系統(tǒng)的速度。
在 Saturn Cloud 上創(chuàng)建免費帳戶后,打開服務(wù)并轉(zhuǎn)到“資源”頁面。從那里,查看預(yù)制的資源模板,并單擊標記為 RAPIDS 的模板。
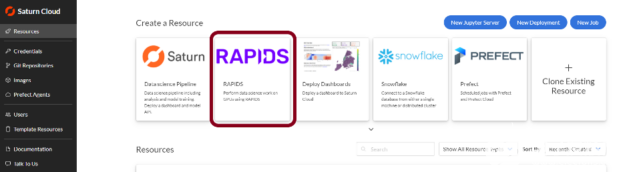
圖 3 : Saturn Cloud 預(yù)先配置了 RAPIDS 圖像,以便于使用 GPU s 。
您將被帶到新創(chuàng)建的資源。這里的一切都已設(shè)置好,您可以在 GPU 硬件上運行代碼, Docker 映像安裝了所有必要的 Python 和 RAPIDS 軟件包。
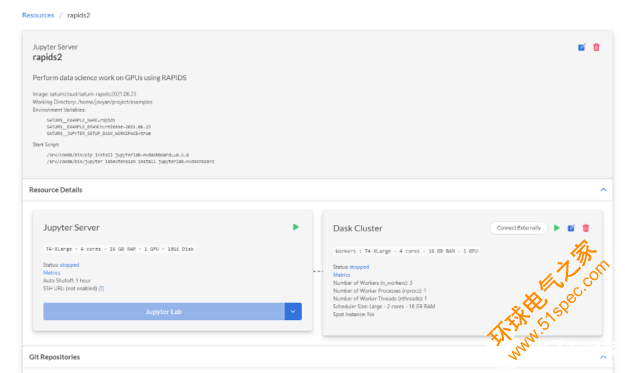
圖 4 : Saturn Cloud 建立了一個裝備了 RAPIDS 的 Jupyter 服務(wù)器和 Dask 集群。
開箱即用的環(huán)境包括:
4 v CPU s ,帶 16 GB RAM
NVIDIA T4 GPU 16GB 的 GPU RAM
RAPIDS: including cuDF, cuML, XGBoost, 還有更多
NVDashboard JupyterLab 擴展,用于實時 GPU 指標
用于監(jiān)視集群的 Dask 和Dask JupyterLab 擴展
常見的 PyData 包,如 NumPy 、 SciPy 、 pandas 和 scikit-learn
單擊“ Jupyter 服務(wù)器”和“ Dask 群集”卡上的播放按鈕啟動資源。現(xiàn)在,您的集群已準備就緒;繼續(xù)了解 GPU 如何顯著加快模型訓(xùn)練時間。
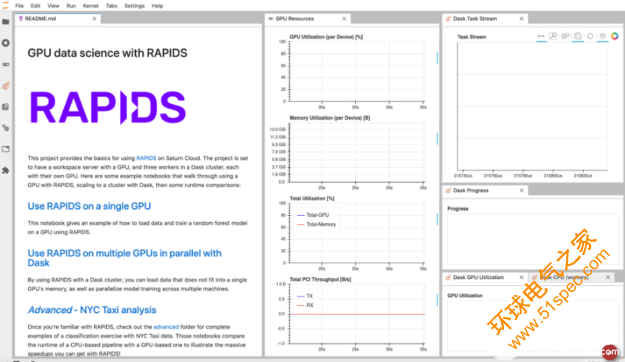
圖 5 :具有單個和多個 GPU 后端的預(yù)構(gòu)建 RAPIDS 環(huán)境。
用 RAPIDS 訓(xùn)練隨機森林模型
對于本練習(xí),我們將使用紐約出租車數(shù)據(jù)集。我們將加載一個 CSV 文件,選擇我們的功能,然后訓(xùn)練一個隨機森林模型。為了說明在 GPU 上使用 RAPIDS 可以實現(xiàn)的運行時加速,我們將首先使用傳統(tǒng)的基于 CPU 的 PyData 包,如 pandas 和 scikit learn 。
我們的機器學(xué)習(xí)模型回答了以下問題:
根據(jù)行程開始時已知的特征,該行程是否會導(dǎo)致高小費?
這里的因變量是“小費百分比”,即小費的美元金額除以乘坐成本的美元金額。我們將使用取貨目的地、下車目的地和乘客數(shù)量作為自變量。
接下來,您可以將下面的代碼塊復(fù)制到 Saturn Cloud JupyterLab 界面中的新筆記本中。或者,您可以下載整個筆記本都在這里。首先,我們將設(shè)置一個上下文管理器來計時代碼的不同部分:
from time import time
from contextlib import contextmanager
times = {}
@contextmanager
def timing(description: str) -> None:
start = time()
yield
elapsed = time() - start
times[description] = elapsed
print(f"{description}: {round(elapsed)} seconds")
然后,我們將從紐約出租車 S3 存儲桶中取出一個 CSV 文件。注意,我們可以將文件直接從 S3 讀入數(shù)據(jù)幀。但是,我們希望將網(wǎng)絡(luò) IO 時間與 CPU 或 GPU 上的處理時間分開,如果我們希望在數(shù)十次修改后運行此步驟,我們就不必多次承擔(dān)網(wǎng)絡(luò)成本。
!卷曲 https :// s3 。 Amazon aws 。 com / nyc tlc / trip + data / yellow _ tripdata _ 2019-01 。 csv 》 data 。 csv
在討論 GPU 部分之前,讓我們先看看傳統(tǒng)的 PyData 軟件包(如 pandas 和使用 CPU 進行計算的 scikit )的情況。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier as RFCPU
with timing("CPU: CSV Load"):
taxi_cpu = pd.read_csv(
"data.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
)
X_cpu = (
taxi_cpu[["PULocationID", "DOLocationID", "passenger_count"]]
.fillna(-1)
)
y_cpu = (taxi_cpu["tip_amount"] > 1)
rf_cpu = RFCPU(n_estimators=100, n_jobs=-1)
with timing("CPU: Random Forest"):
_ = rf_cpu.fit(X_cpu, y_cpu)
CPU 代碼需要幾分鐘的時間,因此請繼續(xù)并為 GPU 代碼打開一個新的筆記本。您會注意到, GPU 代碼看起來幾乎與 CPU 代碼相同,只是我們將“ pandas ”替換為“ cuDF ”,將“ scikit learn ”替換為“ cuml ”。 RAPIDS 包有意地類似于典型的 PyData 包,使您的代碼盡可能容易地在 GPU 上運行!
import cudf
from cuml.ensemble import RandomForestClassifier as RFGPU
with timing("GPU: CSV Load"):
taxi_gpu = cudf.read_csv(
"data.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
)
X_gpu = (
taxi_gpu[["PULocationID", "DOLocationID", "passenger_count"]]
.astype("float32")
.fillna(-1)
)
y_gpu = (taxi_gpu["tip_amount"] > 1).astype("int32")
rf_gpu = RFGPU(n_estimators=100)
with timing("GPU: Random Forest"):
_ = rf_gpu.fit(X_gpu, y_gpu)
You should have been able to copy this into a new notebook and execute the whole thing before the CPU version finished. once that’s done, check out the difference in the runtimes of each.
使用 CPU , CSV 加載耗時 13 秒,而隨機森林訓(xùn)練耗時 364 秒( 6 分鐘)。使用 GPU , CSV 加載耗時 2 秒,而隨機森林訓(xùn)練耗時 18 秒。這就是快 7 倍 CSV 加載和快 20 倍隨機林訓(xùn)練。

圖 6 : RAPIDS + Saturn Cloud 幫助用戶解決他們的挑戰(zhàn),而不是等待進程。
使用 RAPIDS + Dask 解決大數(shù)據(jù)問題
雖然單個 GPU 對于許多用例來說足夠強大,但現(xiàn)代數(shù)據(jù)科學(xué)用例通常受益于越來越大的數(shù)據(jù)集,以生成更準確、更深刻的 i NSight s 。許多用例都需要由多個 GPU 或節(jié)點組成的橫向擴展基礎(chǔ)架構(gòu),以便在工作負載中快速切換。 RAPIDS 與 Dask 很好地匹配,以支持橫向擴展到大型 GPU 集群。
from dask.distributed import Client, wait
from dask_saturn import SaturnCluster
import dask_cudf
from cuml.dask.ensemble import RandomForestClassifier as RFDask
cluster = SaturnCluster()
client = Client(cluster)
taxi_dask = dask_cudf.read_csv(
"s3://nyc-tlc/trip data/yellow_tripdata_2019-*.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
storage_options={"anon": True},
assume_missing=True,
)
X_dask = (
taxi_dask[["PULocationID", "DOLocationID", "passenger_count"]]
.astype("float32")
.fillna(-1)
)
y_dask = (taxi_dask["tip_amount"] > 1).astype("int32")
X_dask, y_dask = client.persist([X_dask, y_dask])
_ = wait(X_dask)
rf_dask = RFDask(n_estimators=100)
_ = rf_dask.fit(X_dask, y_dask)
使用 RAPIDS 和 Saturn Cloud 簡化加速數(shù)據(jù)科學(xué)
此示例顯示了在 GPU 或 GPU Dask 集群上使用 RAPIDS 加速數(shù)據(jù)科學(xué)工作負載是多么容易。使用 RAPIDS 可以將訓(xùn)練時間增加一個數(shù)量級,這可以幫助您更快地迭代模型。有了 Saturn Cloud ,你可以在需要的時候啟動 Jupyter 筆記本電腦、 Dask 集群和其他云資源。
關(guān)于作者
Jacob Schmitt 是 NVIDIA 企業(yè)數(shù)據(jù)科學(xué)產(chǎn)品團隊的產(chǎn)品營銷經(jīng)理,他幫助企業(yè)用戶連接到強大的數(shù)據(jù)科學(xué)解決方案。在加入 NVIDIA 之前,他是 Capital One 機器學(xué)習(xí)中心的產(chǎn)品經(jīng)理,推動了諸如 Dask 和 RAPIDS 等強大開源庫的采用和擴展。
Jacqueline Nolis 博士是一位數(shù)據(jù)科學(xué)領(lǐng)導(dǎo)者,在 DSW 和 Airbnb 等公司管理數(shù)據(jù)科學(xué)團隊和項目方面擁有超過 15 年的經(jīng)驗。她目前是 Saturn Cloud 的數(shù)據(jù)科學(xué)負責(zé)人,她幫助為數(shù)據(jù)科學(xué)家設(shè)計產(chǎn)品。杰奎琳有博士學(xué)位。在工業(yè)工程和合著本書建立在數(shù)據(jù)科學(xué)的職業(yè)生涯。
審核編輯:郭婷
使用 Saturn Cloud ,您可以從我們之前使用的同一項目連接到 GPU 供電的 Dask 集群。然后,要在 GPU 上使用 Dask ,您需要將cudf包替換為dask_cudf以加載數(shù)據(jù),并使用cuml.dask子模塊進行機器學(xué)習(xí)。現(xiàn)在請注意,我們在dask_cudf.read_csv中使用 glob 語法加載 2019 年的所有數(shù)據(jù),而不是像以前那樣加載一個月的數(shù)據(jù)。這與我們前面的示例一樣處理大約12x的數(shù)據(jù)量,但只使用 GPU 集群處理90 秒。